

Los principios éticos de la inteligencia artificial se convirtieron en dogmas tecnológicos que prometen desarrollo, bienestar y un mejor futuro sin preguntarse qué es el desarrollo, para quiénes y a qué costo es ese bienestar, ni si existe un consenso sobre qué entendemos por “un mejor futuro”. Lejos de ser neutral y objetiva, la IA refuerza estructuras de poder dominantes, trae consecuencias ambientales enormes y amplía la brecha digital a nivel mundial, concentrando el poder en un puñado de actores dentro del sector privado y en el Norte Global. Desde el Sur ―escribe Sofía Trejo― debemos preguntarnos si existen caminos que nos permitan transitar hacia otros paradigmas de lo tecnológico alineados con nuestras propias visiones e intereses.
Por: Sofía Trejo/ Arte: RNDR Martinez
Esta nota es una adaptación de un texto publicado originalmente en Inteligencia Artificial Feminista: hacia una agenda de investigación en América Latina y el Caribe.
En los últimos años, gobiernos, organismos internacionales, academia, sociedad civil y sector privado han formulado un sin número de principios de la Inteligencia Artificial (IA) con la intención de alinear el desarrollo de esta tecnología con el bienestar, la ética o la sostenibilidad. Pese a existir más de ciento sesenta propuestas para desarrollar IA de forma “ética” o “responsable», es poco el trabajo enfocado en estudiar de forma crítica estos principios y la factibilidad de que sean utilizados para guiar el desarrollo tecnológico. En otras palabras, los principios éticos de la IA se han convertido en dogmas tecnológicos que nos prometen desarrollo, bienestar y un mejor futuro, sin preguntarse qué es el desarrollo, para quiénes es el bienestar y a qué costo, ni si existe un consenso sobre qué entendemos por “un mejor futuro”.
Estos principios, como consecuencia, tienden a reforzar narrativas tecnológicas que asumen la universalidad de valores, de visiones de mundo y de futuro. Además, nutren la narrativa de que la tecnología (particularmente la IA) es neutra y objetiva y que puede fungir como el gran igualador en el mundo. Pero ¿es posible afirmar que la tecnología sea neutra? ¿o será que la técnica misma codifica valores al desarrollarla? Y si así fuera, ¿qué valores son y hacia dónde guían el desarrollo tecnológico?
No debería sorprendernos que la respuesta a las preguntas anteriores sea que lejos de ser neutral y objetiva, la IA refuerza estructuras de poder dominantes, particularmente el capitalismo, el colonialismo y el patriarcado. De manera más preocupante, lejos de fungir como el «gran igualador», la IA está ampliando la brecha digital a nivel mundial, concentrando el poder en un puñado de actores dentro del sector privado (los gigantes tecnológicos) y en el Norte Global. Por lo tanto, es de suma importancia que desde el Sur nos preguntemos hasta qué punto es posible direccionar este fenómeno tecnológico, hacia dónde y si existen caminos que nos permitan transitar hacia otros paradigmas de lo tecnológico alineados con nuestras visiones e intereses.
La buena noticia es que ¡otros futuros tecnológicos son posibles! Pero antes de proponer alternativas, es importante entender cómo llegamos hasta acá. ¿Cómo se consolidaron las estructuras de poder en el campo de la IA a través de la estrecha relación entre técnica y práctica?
La IA puede ser creada mediante diversas arquitecturas. La más utilizada en la actualidad se llama machine learning (aprendizaje automático). Este tipo de sistemas aprenden a emular comportamientos en base a ejemplos de dicho comportamiento que son presentados al sistema en forma de datos. Por tanto, si quisiéramos crear un sistema de IA que clasifique imágenes de animales por especie, deberíamos mostrarle numerosas imágenes de ejemplares de cada una de las especies. El sistema podría crear un modelo de clasificación utilizando los datos que le fueron presentados en la etapa de aprendizaje, conocida, también, como de etapa de entrenamiento.
Los datos utilizados durante la etapa de entrenamiento se convierten en la realidad que el sistema va a reproducir. Si los datos reflejan, por ejemplo, desigualdad o discriminación (como la de género) es muy probable que estos patrones sean aprendidos y reproducidos por el sistema (algo que ocurre frecuentemente). El machine learning, lejos de ser neutral u objetivo, está diseñado para reproducir patrones. Esto se debe a que estos sistemas son construidos usando estadística y se basan en encontrar patrones y relaciones entre los datos. Este enfoque, aunque produce resultados asombrosos como el Chat-GPT, tienen el defecto de generar predicciones cuyas lógicas precisas no podemos entender. Es por esto que los sistemas de aprendizaje de máquina son llamados también cajas negras.
Aunque no podamos entender cómo o por qué un modelo de aprendizaje de máquina hizo determinada predicción, sí podemos evaluar qué tan bueno es para emular el comportamiento deseado. Para evaluarlo se le muestran datos que no haya visto antes (datos de evaluación) y se estudia la calidad de sus predicciones. La forma más utilizada para evaluar el desempeño de un sistema se llama exactitud. De manera muy general, podemos pensar en la exactitud como el porcentaje de predicciones correctas que hace un sistema dividido entre cien. Si evaluamos nuestro sistema de clasificación animales por especie con un conjunto de 100 imágenes y este clasifica 80 correctamente, el porcentaje de predicciones correctas es del 80% y la exactitud es 0.8. Dado que el incremento en la exactitud está relacionado con un aumento del porcentaje de predicciones correctas, una enorme cantidad de trabajo sobre IA se ha enfocado en optimizar esta métrica bajo la premisa de que mayor exactitud equivale a mayor progreso en el campo. ¿Pero es realmente así?
Más que una cantidad o un porcentaje, podemos pensar en la exactitud como una manera de codificar qué es considerado importante para el desarrollo de IA y cómo se mide esa importancia. Esta métrica representa una valorización. Pero ¿qué favorece esta valorización?, ¿qué impactos tiene esta métrica en el desarrollo tecnológico?, ¿es posible redireccionar la tecnología mediante valorizaciones distintas? Para explorar estos interrogantes es importante entender el desarrollo histórico de la IA en las últimas dos décadas.
Hoy son tres los factores clave para el avance de la IA: la innovación de algoritmos, los datos y la cantidad de cómputo usada para el entrenamiento de los sistemas; esto último corresponde al número de cálculos u operaciones matemáticas que se realizan para crear los modelos. En particular, el cómputo es el mejor indicador de la exactitud, dado que el entrenamiento de sistemas de aprendizaje de máquina depende de la optimización del valor de los parámetros (o las variables) de los cuáles depende el modelo. En otras palabras, incrementar la exactitud de sistemas, particularmente del aprendizaje automático, requiere un incremento del cómputo utilizado para entrenarlos, ya que esto permite encontrar más relaciones y patrones entre los datos (codificadas en los parámetros). Esta relación entre el número de parámetros y la exactitud de los sistemas ha llevado a un incremento constante en la complejidad de los modelos, que cada vez dependen de más y más parámetros. Para darnos una idea de la velocidad de estos cambios, ELMo (uno de los mayores modelos de procesamiento del lenguaje natural), desarrollado en 2018, tenía 94 millones de parámetros; GPT-3 (el modelo utilizado como base para Chat-GPT), producido en 2020, depende de 175 billones; mientras que GPT-4 (la nueva versión de GPT-3), producido en 2023, tiene más de un trillón.

Para entender el estado actual del campo de la IA y para reflexionar sobre sus posibles futuros, es fundamental analizar los requerimientos computacionales de los sistemas y los impactos que han tenido en distintos actores y regiones del mundo.
Por más de seis décadas, entre 1950 y 2011, la cantidad de cómputo utilizada para desarrollar sistemas de IA siguió un patrón similar al de la Ley de Moore, duplicándose cada dos años [1]. Durante esta etapa, diversos grupos de investigación utilizaban el mismo tipo de software y de hardware, y el equipo de cómputo tenía propósitos generales [2]. Sin embargo, el año 2012 marcó el inicio de una nueva era en el desarrollo de IA. A partir de este momento la tasa de cómputo utilizada para entrenar modelos de IA comenzó a duplicarse cada 3,4 meses [3].
Este cambio drástico en la utilización de cómputo está relacionada con la introducción de hardware especializado para procesamiento, en particular con el uso de Unidades de Procesamiento Gráfico (GPU)[4]. Las unidades GPU existían antes de 2012, pero eran utilizadas principalmente para videojuegos y animaciones gráficas. Después del 2012 el hardware especializado se convirtió en una pieza clave para el desarrollo de la IA. Actualmente, grandes empresas de tecnología como Amazon, Apple, Google y Tesla trabajan en el diseño de hardware especializado[5]. En muchos casos este hardware, como las Unidades de Procesamiento Tensorial (TPU) creadas por Google, es de uso exclusivo para las compañías que lo desarrollan o es accesible para desarrolladores externos exclusivamente mediante servicios de nube (Google Cloud). Esto trae consecuencias negativas como el aumento de la dependencia hacia grandes compañías de tecnología para el desarrollo de IA. Además, aunque los equipos puedan ser rentados, los costos para crear modelos de IA de última línea (estado del arte) es extremadamente alto, lo que los hace totalmente inaccesibles para la mayoría de los grupos de investigación; en 2021 los costos de los grandes modelos estaba muy por debajo del millón de dólares (con excepciones), mientras que en 2022 ya superan esta cifra[6].
El desarrollo de hardware especializado y de otras infraestructuras digitales, por lo tanto, ha colaborado en la creación de un oligopolio que controla gran parte de los recursos computacionales requeridos para crear sistemas de IA de alto desempeño. Es decir, el aumento de la cantidad de cómputo requerida para crear sistemas de IA ha influenciado significativamente el desarrollo del campo al favorecer solo a un pequeño grupo de actores.
Uno de los cambios más significativos en el desarrollo de la IA en esta nueva etapa, post Moore y post 2012, es que los grupos de investigación han dejado de estar en circunstancias comparables. Esto se debe a que en este campo el acceso a cómputo está fuertemente ligado con la producción de los resultados de alto nivel, por lo que aquellos grupos sin acceso a hardware especializado ―y sin la capacidad de crear el software requerido para implementarlo― están en desventaja [9]. En otras palabras, a partir del 2012 se abrió una brecha de cómputo que provocó la centralización de la producción de conocimiento sobre IA en grupo pequeño de actores (varios de ellos grandes empresas de tecnología) des-democratizando el campo [10]. Además, estos cambios han generado que los grupos que actualmente producen los mejores sistemas de IA (basados en exactitud o en métricas relacionadas) lo hagan a través del uso de cantidades masivas de cómputo, lo que esencialmente significa que están comprando mejores resultados [11].
***
Este nuevo paradigma tecnológico no ha afectado a todas las regiones del mundo de la misma forma. De hecho, ha favorecido al Norte Global y ha limitado el desarrollo tecnológico en diversas regiones del Sur. El gráfico 1 muestra el porcentaje de publicaciones (revisadas por pares) producidas en diversas regiones a nivel mundial [12]. El porcentaje de representación de América Latina y el Caribe en el campo ha estado decreciendo, marginal pero constantemente, desde 2012. De manera complementaria, en las últimas dos décadas la participación de empresas tecnológicas (como Google y Facebook) en las principales conferencias de IA ha incrementado y actualmente estas empresas representan aproximadamente el 30% de los trabajos en estos espacios[13].
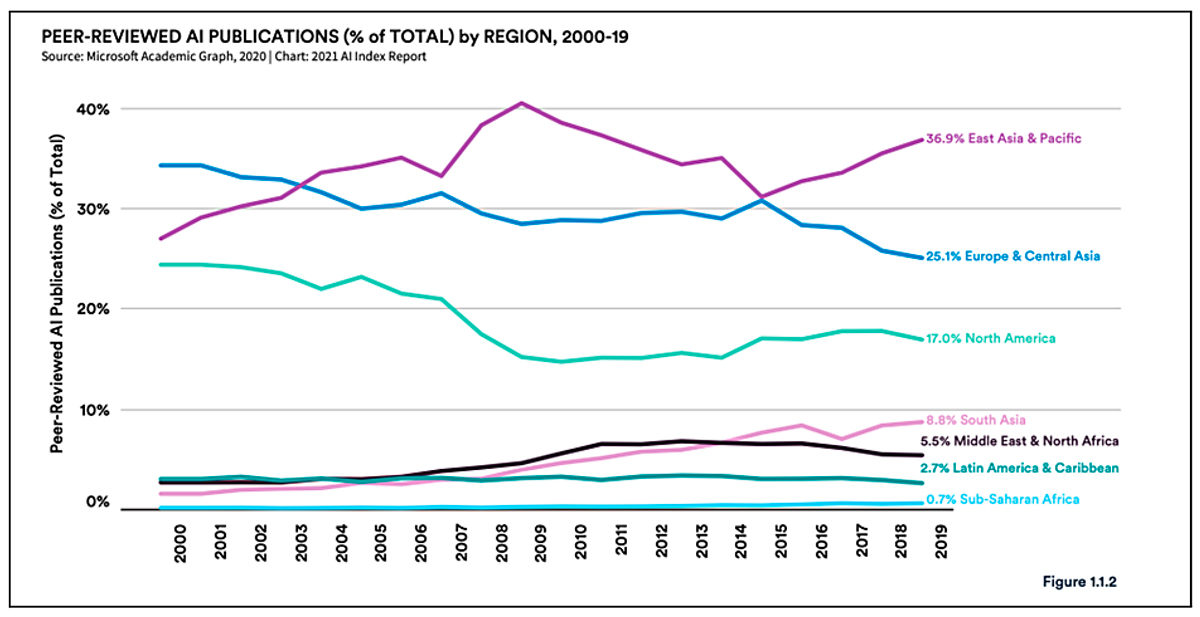
Gráfico 1
Crear sistemas de IA tiene altos costos económicos y ambientales. Hoy el entrenamiento de un sistema de IA de última generación requiere millones de dólares. Por lo que desarrollar este tipo de tecnología está fuera del alcance de la mayoría de los grupos de investigación, particularmente de aquellos en el Sur Global. Por otro lado, la enorme cantidad de cómputo requerida para crear estos sistemas ha provocado que el entrenamiento de un único sistema de IA produzca emisiones de gases invernadero comparables a las emisiones combinadas de 5 automóviles a lo largo de toda su vida útil, incluyendo la manufactura.
Mejorar el desempeño de la IA ha tenido consecuencias significativas en el desarrollo del campo a nivel global, principalmente el incremento de los costos e impactos ambientales asociados al desarrollo de estos sistemas y en la desigualdad. ¿Qué ganamos, entonces, con este enfoque de desarrollo? ¿Existen otros caminos posibles?
Aunque la exactitud mide qué tan buenos son los sistemas para predecir un comportamiento, los incrementos en esta métrica no hacen que esta tecnología sea más inteligente. Esto es relevante porque en la actualidad gran parte de la investigación en IA está enfocada en diseñar sistemas con mayor desempeño (es decir, mayor exactitud) en pruebas específicas, y en crear nuevas pruebas una vez que las existentes han sido superadas [14]. Existe poca claridad, sin embargo, sobre si esta forma de desarrollar IA efectivamente crea sistemas con mayor inteligencia o si en realidad los resultados dependen de enormes cantidades de cómputo y datos (en otras palabras, de la estadística)[15]. Por estos motivos, algunas expertas, entre ellas Timnit Gebru, abogan por un cambio en las metas de investigación que guían la IA y proponen dejar de priorizar el diseño de sistemas que mejoren el desempeño en pruebas específicas, para poner énfasis en investigación que ayude a entender cómo es que las máquinas superan estas pruebas[16]. En síntesis, se propone redireccionar las líneas de investigación en IA para mejorar el entendimiento de la manera en la que operan los sistemas, en lugar de seguir produciendo sistemas más exactos cuyo funcionamiento no entendemos.
Sería interesante pensar si es posible desarrollar estrategias que de manera conjunta permitan aminorar otras problemáticas derivadas de la excesiva importancia que el campo le ha dado a la exactitud, como el incremento de la desigualdad y de los impactos ambientales. Afortunadamente, el trabajo sobre IA y cambio climático podría servir como apoyo para proponer alternativas. En particular, estudios recientes [17] han identificado a la eficiencia como una métrica más adecuada que la exactitud para evaluar los sistemas de IA. Esto es así porque la eficiencia significa reportar la cantidad de trabajo requerido para producir un resultado de IA [18], algo que incluye cuantificar el trabajo requerido para entrenar el modelo y, de ser aplicable, el trabajo utilizado para todos los experimentos de calibración (hyperparamenter tuning). Algunas de las ventajas de la eficiencia sobre la exactitud son que esta métrica permite cuantificar impactos ambientales y favorece mejoras en manejo de recursos (en lugar de favorecer el uso de mayores cantidades de cómputo). En este sentido, la eficiencia permite hacer comparaciones más justas entre sistemas, ya que toma en consideración la cantidad de recursos utilizados para crear los modelos.
Definir qué se entiende por eficiencia, sin embargo, no es una tarea sencilla. Si queremos que esta métrica sirva para comparar sistemas debe ser independiente del laboratorio, del tiempo y del hardware utilizado. Y encontrar la forma de satisfacer estos requerimientos de forma simultánea no es fácil. Por ejemplo, podría parecer una buena idea definir la eficiencia de un sistema de IA tomando en consideración la cantidad de emisiones de carbono generadas durante su desarrollo. El problema con esta propuesta es que las emisiones generadas por sistemas de IA dependen de las emisiones de la red eléctrica, y estas varían sustancialmente dependiendo de la localidad y de los tipos de energía (eléctrica, eólica, hidráulica, etc.)[19]. Por lo que las emisiones de carbono producidas por un sistema de IA dependen del lugar en donde este fue desarrollado.
Tomando en cuenta esta dependencia entre la localidad y los impactos ambientales, se podría proponer medir la eficiencia tomando en cuenta la cantidad de electricidad utilizada para crear cada modelo, en lugar de las emisiones de carbono. Esta propuesta tiene la ventaja de ser independiente tanto del tiempo como de la localización. Además, la mayoría de los GPU’s reportan la cantidad de electricidad que consumen, lo que facilita el cálculo de la cantidad de electricidad requerida para generar cada modelo de IA. Sin embargo, esta métrica tiene un inconveniente: el consumo de energía utilizado para crear un modelo depende del hardware que se haya utilizado [20]. Por lo tanto, usar la cantidad de energía requerida para crear el sistema como métrica es independiente del tiempo y de la localización, pero no es independiente del equipo. Esto quiere decir que encontrar nuevas métricas que permitan hacer comparaciones más justas entre los sistemas y que tomen en cuenta los impactos ambientales generados por esta tecnología no es trivial. Estas valorizaciones deberán tomar en cuenta que los sistemas de IA son producidos en diversas localidades, que varían tanto en equipo como en infraestructuras, lo que afecta la capacidad de cómputo e impactos ambientales derivados de cada desarrollo tecnológico.
Definir nuevas valorizaciones que permitan guiar el desarrollo de la IA hacia una mayor equidad y sostenibilidad dependerá de una reflexión profunda sobre qué queremos priorizar y cuál sería la mejor manera de hacerlo. Como hemos visto, este proceso debe estar acompañado de un entendimiento de las relaciones de poder y la manera en la que estas permean tanto con la técnica como con la práctica. Es en estas conversaciones que las perspectivas del Sur Global tienen mucho que aportar, dado que diseñar estrategias para guiar esta tecnología hacia nuevos horizontes requerirá conceptualizar intervenciones que permitan redireccionar los diversos procesos involucrados en este desarrollo tecnológico, tomando en consideración la manera en la que estos se interrelacionan con experiencias y contextos específicos. El cambio no será fácil, pero una cosa es clara: otros caminos son posibles. Construirlos dependerá nuestra capacidad de crear estrategias conjuntas que nos permitan caminar hacia ellos.
[1] Ahmed, N., & Wahed, M. (2020). The de-democratization of ai: Deep learning and the compute divide in artificial intelligence research. arXiv preprint arXiv:2010.15581.
[2] idem
[3] Amodei, D., & Hernandez, D. (2021, June 21). AI and Compute. OpenAI. https://openai.com/blog/ai-and-compute/
[4] idem
[5] Ahmed, N., & Wahed, M. (2020). The de-democratization of ai: Deep learning and the compute divide in artificial intelligence research. arXiv preprint arXiv:2010.15581.
[6] 2023 State of AI in 14 charts. (2023, April). Stanford HAI. Retrieved August 24, 2023, from https://hai.stanford.edu/news/2023-state-ai-14-charts
[7] Shalf, J. (2020). The future of computing beyond Moore’s Law. Philosophical Transactions of the Royal Society A, 378(2166), 20190061.
[8] idem
[9] Ahmed, N., & Wahed, M. (2020). The de-democratization of ai: Deep learning and the compute divide in artificial intelligence research. arXiv preprint arXiv:2010.15581.
[10] idem
[11] Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green ai. Communications of the ACM, 63(12), 54-63.
[12] Daniel Zhang, Saurabh Mishra, Erik Brynjolfsson, John Etchemendy, Deep Ganguli, Barbara Grosz, Terah Lyons, James Manyika, Juan Carlos Niebles, Michael Sellitto, Yoav Shoham, Jack Clark, and Raymond Perrault, “The AI Index 2021 Annual Report,” AI Index Steering Committee, Human-Centered AI Institute, Stanford University, Stanford, CA, March 2021.
[13] Ahmed, N., & Wahed, M. (2020). The de-democratization of ai: Deep learning and the compute divide in artificial intelligence research. arXiv preprint arXiv:2010.15581.
[14] Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?🦜. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610-623).
Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green ai. Communications of the ACM, 63(12), 54-63.
[15] Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?🦜. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610-623).
[16] idem
[17] Cowls, J., Tsamados, A., Taddeo, M., & Floridi, L. (2021). The AI gambit: leveraging artificial intelligence to combat climate change—opportunities, challenges, and recommendations. Ai & Society, 1-25.
Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green ai. Communications of the ACM, 63(12), 54-63.
[18] Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green ai. Communications of the ACM, 63(12), 54-63.
[19] Cowls, J., Tsamados, A., Taddeo, M., & Floridi, L. (2021). The AI gambit: leveraging artificial intelligence to combat climate change—opportunities, challenges, and recommendations. Ai & Society, 1-25.[20]Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green ai. Communications of the ACM, 63(12), 54-63.


